
الكاتب: د. علي ياسين

الكاتب: د. وسيم رمضان
1- مقدمة
نتيجة ازدياد كم البيانات المتوافر في كل مكان بشكل كبير في الآونة الأخيرة (من المتوقع أن يصل إنتاج البيانات إلى Zettabytes 175 بحلول عام 2025)[1] ، أَصْبَحَ هناك حاجة ضرورية لتحليل مجموعات البيانات في العالم الحقيقي بكافة أشكالها واستخراج أنماط البيانات الخفيّة والمعقدة لاستخدامها في العديد من المجالات المختلفة. يتأثر تحليل البيانات في مختلف المجالات التطبيقية بالبيانات الشاذة التي يمكن أن تكون مؤشراً على شيء خارج نطاق البيانات الطبيعية. وبالتالي، يجب أن يميز التحليل السليم للبيانات بين البيانات الطبيعية وغير الطبيعية من أجل الحصول على المعلومات الصحيحة والدقيقة والمعبرة عن الحالة الطبيعية. وهذا ما يدعو للحاجة إلى الاهتمام بشكل أو بآخر بالكشف عن الشذوذ.
آثار الشذوذ في البيانات
تُشير نقاط البيانات الشَّاذَّة إلى تلك التي تختلف بشكلٍ ملحوظ عن النمط أو السلوك المتوقع. يُمكن أن يكون لهذه النقاط تأثيرٌ سلبيٌّ كبيرٌ على نماذج تحليل البيانات ونماذج التنبؤ، مما يؤدي إلى نتائج غير دقيقة. ومن اهم الآثار السلبية:
تشويه نماذج البيانات: تُمكن أن تؤدي نقاط البيانات الشَّاذَّة إلى تشويه نماذج البيانات، مما يجعلها غير دقيقة وغير موثوقة. على سبيل المثال، في نموذج يتنبأ بسعر الأسهم، قد تؤدي نقطة بيانات شَّاذَّة تمثل صفقةً ضخمةً غير عادية إلى إفساد النموذج بأكمله.
إخفاء الأنماط الحقيقية: قد تُخفي نقاط البيانات الشَّاذَّة الأنماط الحقيقية في البيانات، مما يجعل من الصعب استخلاص رؤى واقعية. على سبيل المثال، في مجموعة بيانات طبية، قد تُخفي نقطة بيانات شَّاذَّة تمثل مريضاً ذا حالة طبية نادرة نمطاً مهماً يشير إلى انتشار مرض معين.
القرارات الخاطئة: قد تؤدي نقاط البيانات الشَّاذَّة إلى اتخاذ قرارات خاطئة. على سبيل المثال، في نظام الكشف عن الاحتيال، قد تؤدي نقطة بيانات شَّاذَّة تمثل معاملة احتيالية وهمية إلى رفض معاملة مشروعة.
يتناول هذه المقال على نحوٍ أساسي تعريف وتحليل شامل لمفهوم الشُّذُوذ، وكيفية معالجته وتأثيره على مختلف المجالات العملية.
تَهَدُّف عملية الكشف عن الحالات الشاذة [2] إلى تحديد كل نقاط البيانات التي تسلك سلوكاً مختلفاً عن باقي نقاط المجموعة. يُمْكَنْ أن تنتج الحالات الشاذة عن خطأ في البيانات؛ ولكنها تدل أيضاً على عمليات أساسية جديدة لم تكن معروفة مسبقاً وغالباً ما تكون حرجة في مجموعة واسعة من التطبيقات.
هناك مجموعة من التَّحَدِّيَات [3] التي تَجعَل من عملية اكتشاف الشُّذُوذ عملية مُعَقَّدَةَ، على عكس تلك المجالات التي تَكَون فيها الأنماط مُنتَظمة وواضحة. ومنها:
1. نقص المعرفة (Lack of Knowledge): تَرْتَبِطُ الحالات الشَّاذَّة بالعديد من الأشياء المجهولة، مثل الحالات ذات السلوكيات المفاجئة وتوزيع الحالات الشَّاذَّة التي تَبْقَى غير معروفة حتى تَحَدث فعلاً.
2. عدم تجانس الشُّذُوذ (Heterogeneous Anomaly): قَدْ تَسْلُك بعض حالات الشُّذُوذ سلوكاً مختلفاً تماماً عن الحالات الشَّاذَّة الأخرى.
3. ندرة البيانات وعدم توازنها (Rarity and Data Imbalance): تُمثّل الحالات الشَّاذَّة عادةً بيانات نادرة، على عكس الحالات الطبيعية التي غالباً ما تَمثّل النسبة الأكبر من البيانات. ومن ثَمَّ فإنه من المستحيل جمع كمية كبيرة من الحالات الشَّاذَّة الْمُصَنَّفَة.
4. تكيّف الأنماط الشَّاذَّة (Adaptation of Anomalous Patterns): يَتَكَيَّف في بعض الأحيان السلوك الشَّاذُّ مع السلوك الطبيعي للبيانات، ومن ثَمَّ يُسَبِّب ذلك صعوبة في تَحْديد الحالات الشَّاذَّة واكتشافها.
5. البيانات عَالِيَّة الْبُعْد (High Dimension Data): قد تكون البيانات ذات أبعاد عالية في المجالات الحديثة (مثل تحليل الصور الطبية أو تحليل النصوص)، مما يُزيد من صعوبة اكتشاف الشذوذ.
6. الأنواع المختلفة للشُّذُوذ (Diverse Types of Anomaly): يوجد مجموعة متنوعة من أنماط الشذوذ، وهي
a. شذوذ النقطة: يَحْدُث عندما يكون عنصر واحد مختلف تماماً عن جميع العناصر المُتَبقّيَة.
b. شذوذ السياق: يحْدُث عندما يَسْلُك العنصر سلوكاً غير طبيعي في سياق محدد.
c. الشذوذ الجماعي: يَحْدُث عندما تكون مجموعة من العناصر التي يرتبطٌ بعضُها ببعضٍ مختلفة تماماً عن باقي العناصر.
هناك إسقاط كبير لمفهوم الشذوذ في تطبيقات العالم الحقيقي ومن أهمها:
كشف الاحتيال: اكتشاف أنشطة غير طبيعية في المعاملات المالية أو أنظمة التأمين
التحكم في الجودة: اكتشاف العيوب في المنتجات الصناعية أو الأخطاء في الخدمات.
الأمن السيبراني: اكتشاف الاختراقات أو الهجمات على الشبكات الحاسوبية.
التشخيص الطبي: اكتشاف الأمراض أو الحالات الطبية غير الطبيعية.
2- تقنيات كشف الشذوذ
تُرَكِّزُ طرائق كشف الشُّذُوذ على تَحْدِيد كُلِّ النقاط التي تَسْلُك سلوكاً مغايراً للمفهوم العام الطبيعي، ويخْتَلِف بعضُها عن بعضٍ بآلية تَمْثيلِ مخرجات الحالات الشَّاذَّة، والتي تكون على نحوٍ عام بإحدى الطريقتين الآتيتين:
1. درجة (Score): تَعْتَمِدُ الطرائق التي تَسْتَنِدُ إلى مفهوم الدرجة على إعطاء كُلِّ نقطة بيانات درجة شُذُوذ، لِيَتِمّ بعد ذلك تَصْنِيف البيانات وفقاً لتِلْكَ الدرجات، إذ تملكُ النقاط الشَّاذَّة درجة شُذُوذ عالية.2. تَمْثيل ثنائي (Binary): تُسْنِد هذه الطرائق تسمية (Label) ثنائية (شَاذَّة أو طبيعية) إلى نقاط البيانات.
يَنْدَرِج تحت هاتين الطريقتين مجموعة من الأساليب والطرائق، وهي كما يلي وفقاً لتسلسل ظهورها التاريخي.
2-1 طرائق الكشف الإحصائية (Statistical Anomaly Detection)
تُعَدُّ التقنيات الإحصائية هي الطرائق الأساسية والتقليدية للكشف عن الشُّذُوذ. تَعْتَمد هذه الطرائق على مبدأ عام واحد، وهو دراسة البيانات الطبيعية أولاً ثَمَّ حساب درجة انحراف كُلّ نقطة في تَدَفُّقَات البيانات عن الوضع الطبيعي، إذ يَكُون للنقاط الشَّاذَّة درجة انحراف عالية. على سبيل المثال، تُستخدَمُ نظرية مربع كاي (Chi-Square) الشهيرة للكشف عن الشُّذُوذ .[4] تَعْتَمِدُ هذه النظرية على إنشاء ملف للبيانات الطبيعية في نظام كشف الشُّذُوذ، ثُمَّ يُحَدِّد النظام جميع الأحداث التي لها درجات انحراف عالية عن الوضع الطبيعي على هيئة أحداث شَاذَّة.
يُمْكِن أيضاً استخدام المتوسط والانحراف المعياري لإيجاد الحالات الشَّاذَّة، إذ تُعْتَبَر جميع النقاط التي تَبْتَعِد عن المتوسط بمقدار انحراف معياري مُعَيَّن نقاطاً شَّاذَّة؛ لكن ذلك لن يفي بالغرض في حالة البيانات التي تُمَثِّل سلسلة زمنية لأن القِيَم غير ثابتة. يُعْتَمَد في تلك الحالة على وجود نافذة مُتَحركة (Rolling Window) لحساب المتوسط عبر نقاط بيانات السلسلة الزمنية، ويُسمّى بالمتوسط المتحرك (Moving Average)[5] .
تعاني الطرائق الإحصائية من عددٍ من التَّحَدِّيَات التي تحد من استخدامها في تطبيقات كشف الشَّذُوذ وهي[6] :
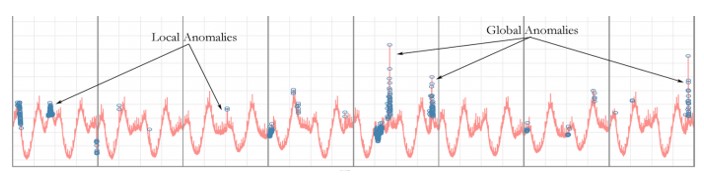
1. تَحْتَوِي البيانات في أغلب الحالات على ضجيج، يَكُون له سلوك مشابه للسلوك الشَاذَّ، ما يسبب صعوبة في تحديد الحالات الشَّاذَّة بدقة.2. تَنْقَسِمُ الحالات الشَّاذَّة إلى شُّذُوذ محلي (Local) وشَذُوذ عام (Global)، إذ يَكُون من السهل الكشف عن الشَّذُوذ العام من خلال الطرائق الإحصائية، على عكس الشُّذُوذ المحلي الذي له أنماط شبيهة بالبيانات الطبيعية.3. صعوبة دراسة العلاقات والأنماط الْخَفِيَّة ضِمْنَ البيانات.4. أَدَّى تَزَايَد كميات البيانات الْمُوَلّدَة إلى قُصُور هذه الطرائق على نحوٍ كبير، وذلك لأنها تَحْتَاج إلى تدخل بشري في كُلّ مرحلة من مراحل عمل النظام.
يوضح الشكل 1 صعوبة تطبيق الطرائق الإحصائية في اكتشاف الحالات الشَّاذَّة المُتَداخلة مع الحالات الطبيعية (الشُّذُوذ المحلي)، يبدو واضحاً من الشكل أن النقاط الشاذة المحلية تقعُ في مناطق قريبة من البيانات الطبيعية.
2-1 طرائق تَعَلُّم الآلة (Machine Learning Methods)
توَجّه الباحثون ضِمْنَ مجال اكتشاف الشُّذُوذ إلى استخدام تقنيات تَعَلُّم الآلة، كما هو الحال في العديد من المجالات المختلفة، لتفادي القصور الحاصل في الطرائق الإحصائية. هناك مجموعة واسعة من طرائق تَعَلُّم الآلة المستخدمة في مجال كشف الشُّذُوذ، وتَنْدَرِج تحت ثلاث فئات رئيسية هي: التصنيف (Classification)، التَّجْمِيع (Clustering)، أقرب جار (Nearest Neighbor).
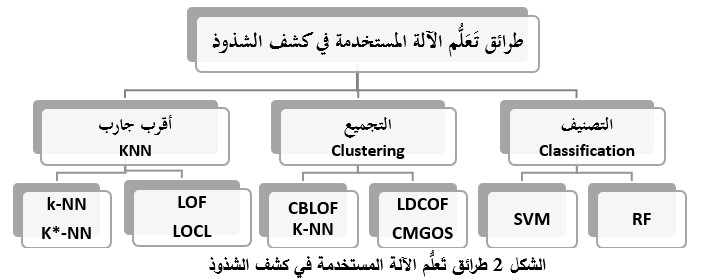
| · LOF: Local Outlier Factor |
| · CBLOF: Cluster-Based Local Outlier Factor |
| · LDCOF: Local Density Cluster based Outlier Factor |
| · CMGOS: Clustering-based Multivariate Gaussian Outlier Score |
| · RF: Random Forest |
| · SVM: Support Vector Machine |
تَنْتَمِي خوارزميات التصنيف إلى التَعَلُّم الخاضع للإشراف (Supervised Learning)، وتَنْتَمِي خوارزميات التَّجْمِيع وأقرب جار إلى التَعَلُّم غير الخاضع للإشراف (Unsupervised Learning).
يَتمُّ تَدْرِيب نموذج كشف الشُّذُوذ باستخدام خوارزميات التصنيف بالاعتماد على بيانات مُصَنَّفَة مسبقاً إلى بيانات طبيعية وشَاذَّة. بينما في النماذج التي تَعْتَمِدُ على خوارزميات التَّجْمِيع، تَتَجَمَّع البيانات المتشابهة ضِمْنَ عناقيد، وتكون جميع النقاط التي لا تَنْتَمِي لهذه العناقيد هي نقاطاً شَاذَّةً. أما بالنسبة إلى خوارزميات أقرب جار فإنها تَفْترِض أَنَّ جميع نقاط البيانات الطبيعية تكون متجاورةً، في حين تكون النقاط الشَّاذَّة بعيدة.
ساعدَ استخدام تقنيات تَعَلُّم الآلة في بناء نماذج كشف الشُّذُوذ على[7] :
1. اكتشاف بعض الاستراتيجيات الجديدة المرتبطة بالسلوك الشَاذّ.2. اكتشاف بعض الأنماط الْمُعَقَّدَة وَالْخَفِيَّة في البيانات.3. دَمَج ملاحظات المراقبين تلقائياً لتحسين دقة الكشف، على عكس الطرائق التقليدية التي تَتَطَلَّب مراجعة القواعد، ومن ثَمَّ تَسْتَغْرِق وقتاً أطول.
على النَّقِيضِ من ذلك، اِصْطَدَمَت هذه التقنيات بمشكلة البيانات غير المتوازنة (Unbalanced Data)، التي يُهَيْمِنُ فِيهَا صف البيانات الأغلبية الطبيعية ((Majority Class على صف الأقلية الشَّاذَّة Minority Class)). تفْرِضُ مُعْظَم تقنيات تَعَلُّم الآلة أن البيانات موزعة على نحوٍ شبه متساوٍ؛ إلا أن ذلك الأمر لا ينطبق على البيانات غير المتوازنة، مِمَّا يُسَبِّب صعوبة في إنشاء نماذج ذات كفاءة عالية نظراً لشح البيانات الشَّاذَّة في مجموعات البيانات. يُؤَدِّي كُلُّ ذلك إلى خلق ما يسمى بمشكلة تَنَاقُض الدِّقَّة Accuracy Paradox))، بمعنى آخر، تكون دقة تصنيف البيانات الطبيعية أعلى من دقة تصنيف البيانات الشَّاذَّة، لذا يفشل النموذج في التنبؤ بالحالات الشَّاذَّة لأن غالبية بيانات التدريب تُمَثِّل بيانات طبيعية. نَقِيس الأمر ذاتهُ على جميع تطبيقات كشف الشُّذُوذ.
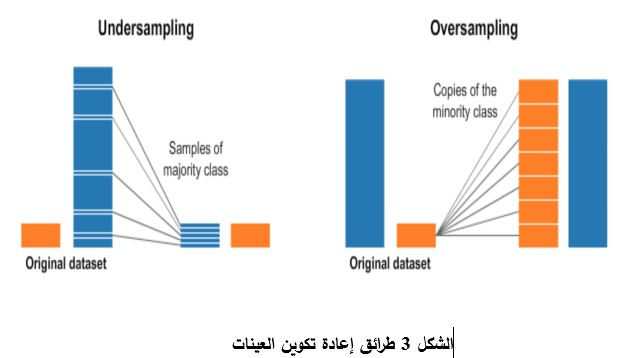
طُوِّر العديد من الأساليب للتغلب على هَذِهِ التَّحَدِّيَات والتخفيف من آثارها، يُمكن تنفيذها في مرحلة ما قبل المعالجة (Pre-Processing). تسمى هذه الأساليب إعادة تكوين العينات (Resampling Methods)، وتعمل على إعادة توازن صفوف البيانات. ومع ذلك، أدت هَذِهِ الأساليب إلى ظهور تَحَدِّيَاتٍ أخرى [8] تَتَمَثَّلُ في: 1) فقدان البيانات المفيدة التي ربما تكون مهمة لعملية الكشف عند استخدام تقنيات تقليل العينات (Under-Sampling)، 2) فرص تخصيص (Overfitting) عند استخدام تقنيات زيادة العينات (Over-Sampling)، بسبب النسخ المتماثل للعينات والَّذِي يُؤَدِّي بدوره إلى التداخل بين الصفوف. يَبْقَى السُّؤَال: هل يجب علينا إعادة التوازن إلى مجموعة البيانات للحصول على أكبر قدر ممكن من البيانات لكلا الصفين؟ أم ينبغي أن يظل صف الأغلبية هو الأكثر تَمْثيلِاً؟ إذا كان الأمر كذلك، فما النسب التي يجب أَنْ نُحَقِّقَهَا لتوازن البيانات؟ لذا يجب استخدام هذه التقنيات بحذر وَأَنْ نَقُومَ بِعَرْضِ النسب الحقيقية لكلا الصفين، يضاف إلى ذلك أن نأخذ بعين الاعتبار مَا تعنيه نتائج النموذج. يُوضّحُ الشكل 3 مفهوم كل من تقنيتي تقليل العينات وزيادة العينات.
2-1 طرائق التَّعَلُّم الْعَمِيق (Deep Learning Methods)
نَتِيجَة تَحَدِّيَات كشف الشُّذُوذ الْمَذْكُورَةِ أعْلَاه الناتجة عن طبيعة المشكلة الْمُعَقَّدَة، كان لا بد من التوجه في الآونة الأخيرة إِلَى بَنَّاء نماذج كشف الشُّذُوذ بالاعتماد على التَّعَلُّم الْعَمِيق. يرجع ذلك للقدرة الكبيرة التي تمتلكها هذه الطرائق في التعامل مع مشكلة اكتشاف الشُّذُوذ، إذ اِسْتَطَاعَتْ أَنْ تَلْعَبَ دوراً هاماً في التخفيف من آثار تلك التَّحَدِّيَاتِ وَمِنْهَا:
1. انخفاض معدل اِسْتِرْجَاع البيانات الشَّاذَّة (Low Anomaly Data Recall Rate)
تُعَانِي معظم طرائق كشف الشُّذُوذ [3] من صعوبة اِسْتِرْجَاع (اكتشاف) جميع الحالات الشَّاذَّة، خاصةٍ تلك التي لها سلوك مشابه للسلوك الطبيعي، بالإضافة إِلى تَحْدِيد الْعَدِيدِ مِنَ الحالات الطبيعية على أنها حالات شَّاذَّة، مِمَّا يُسَبِّب ارتفاعاً في معدلات الإنذارات الكاذبة. يُعدُّ تقليل الإنذارات الكاذبة وتحسين معدلات الْاِسْتِرْجَاع للشُّذُوذ أَحَدَ أَهم التَّحَدِّيَات التي يَصْعُبُ تَحْقِيقُهَا، ولا سيما بالنسبة إلى التكلفة الكبيرة الَّتِي يُسَبِّبُهَا فَشَل اكتشاف الحالات الشَّاذَّة.
2. كشف الشُّذُوذ في البيانات عَالِيَّة الأبعاد (High-Dimensional Data)
كان اكتشاف الشُّذُوذ في بيانات عَالِيَّة الأبعاد [9] مشكلة كبيرة لفترة طويلة من الزمن، إذ تُصبح خصائص البيانات الشَّاذَّة مَخْفِيَّة في فضاء عالي الأبعاد. ظَلّت الطرائق القائمة على اختيار الميزات (Feature Selection) [10] حلاً مباشراً لهذه المشكلة؛ لكن وجود علاقات غير خطية وغير متجانسة حَدّ من فعالية هذه الطرائق. بالإضافة إلى صعوبة اكتشاف الحالات الشَّاذَّة المرتبط بعضها ببعض، مثل العلاقات الزمانية وغيرها من علاقات الترابط.
3. التَّعَلُّم الفعال للحالات الشَّاذَّة (Efficient Learning Anomaly)
نظراً لصعوبة جَمع بيانات الشُّذُوذ الْمُسَمَّاة (Labeled) وتكلفتها، غالباً ما يكون التَّعَلُّم الخاضع للإشراف (Supervised Learning) غير عملي في اكتشاف الشُّذُوذ. تَرَكَّزَت الجهود البحثية في العقد الماضي على استخدام طرائق التَّعَلُّم غير الخاضع للإشراف (Unsupervised Learning) التي لا تَتَطلب أي بيانات تدريب مُصَنَّفَة (مُسَمَّاة)؛ لَكِنها بِالْمُقَابِل تَعْتَمِد عَلَى وضع فرضية حول توزيع البيانات الشَّاذَّة من دون معرفة شاملة وَمُسَبقَةٍ بِهَا، ومن دون أن تكون هذه الفرضية صحيحة دائماً. مِنْ جِهَةِ أُخْرَى، يُمْكِن الْاِسْتِفَادَة من البيانات الطبيعية الْمُصَنَّفَة مسبقاً، بالاعتماد على التَّعَلُّم شبه الخاضع للإشراف (Semi-Supervised Learning) [3]، الَّذِي يَعْتَمِدُ على البيانات الطبيعية الْمُسَمَّاة فقط أثناء عملية التدريب. مِمَّا جَعَلَهُ يُشَكِّلُ اتجاهاً بحثياً في الآونة الأخيرة ضِمْنَ مجال كشف الشُّذُوذ، إذ ساعد عَلَى تَجَاوُز مشكلة شَحّ البيانات الشَّاذَّة في نماذج التصنيف، ومشكلة عدم شمولية الحالات الشَّاذَّة في نماذج التَّجْمِيع.
4. الكشف عن حالات الشُّذُوذ الْمُعُقْدَة (Detection of Complex Anomalies)
تُسْتَخْدَم معظم طرائق كشف الشُّذُوذ الحالية للكشف عن حالات شذوذ النقطة، إذ إنها تفشل في اكتشاف كُلّ مَنْ شُذُوذ السياق والشذوذ الجماعي، وذلك لأن هذه الأنواع من الشُّذُوذ تَتَكَيَّف على نحوٍ أكبر مع الأنماط الطبيعية للبيانات. تَتَمَثَّل أحَد التَّحَدِّيَات في بناء أنظمة لكشف الشُّذُوذ قادرة على التعامل مع كُلّ مَنْ شُذُوذ السياق والشُّذوذ الجماعي.
5. تفسير الشُّذُوذ (Anomaly Explanation)
يُعْتَبِر تَفْسِير الشُّذُوذ في الْعَدِيدِ من التطبيقات الحرجة أمراً هاماً. تُرَكِّزُ مُعْظَمُ نماذج كشف الشُّذُوذ الحالية على اكتشاف الحالات الشَّاذَّة دُونَ تَقْديم تَفْسِير حول السبب المؤدي لتلك الحالات. قَدْ يَكُون لِتَفْسِير الحالات الشَّاذَّة الْمُكْتَشَفَة في بعض التطبيقات أهمية دقة الكشف نفسها. تُوَفِّر طرائق التَّعَلُّم الْعَمِيق بعض الخيارات لتوحيد الشُّذُوذ وتَفْسِيره في إطار عمل واحد، مِمَّا يُؤَدِّي إِلى تَفْسِير أكثر واقعية للأشكال الشَّاذَّة التي رَصْدَتِهَا أنظمة كشف الشُّذُوذ؛ لكنه ما يزال يُمَثِّل تَحَدِّيَاً رئيسياً لتحقيق التوازن الجيد بين قابلية التَّفْسِير وفعالية النظام.
6. تحديد عَتَبَة التصنيف ديناميكياً (Selecting the Classification Threshold)
تَتَطَلَّب نماذج كشف الشُّذُوذ أن تكون قادرة على اختيار عَتَبَة التصنيف (الكشف)، لِلْفَصْلِ بين الحالات الطبيعية والشَّاذَّة. تَخْتَلِف خصَائِص أنظمة كشف الشُّذُوذ وأهدافها حسب مجال التطبيق. ففي بعض التطبيقات، يَكُون لِاِسْتِرْجَاع أكبر عدد ممكن من الحالات الشَّاذَّة أهمية أكبر من دقة الكشف. أما بالنسبة إلى التطبيقات الحرجة، فإن دقة الكشف لَا تَقُل أهمية عن الحالات الشَّاذَّة المكتشفة. لذا يَتِمّ اختيار العَتَبَة تجريبياً على نحوٍ ثابت (Static) بناءً على هدف التطبيق؛ لَكِن ما يَزَال اختيار الْعَتَبَة يُمَثِّل تحدياً رئيساً في أنظمة كشف الشُّذُوذ الحالية، إذ لَا يُمْكِنُهَا اختيار قِيمَة الْعَتَبَة على نحوٍ ديناميكي بِمَا يَتَنَاسَب مَعَ تَغَيُّر حَجم بيانات التطبيق وطبيعتها.
· تَصْنِيف طرائق التَّعَلُّم الْعَمِيق (Categorization of Deep Learning)
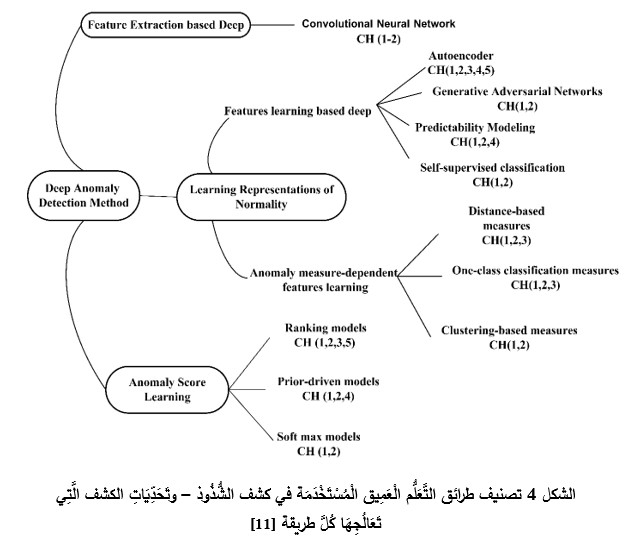
يُمْكِن تَصْنِيف طرائق التَّعَلُّم الْعَمِيق في الكشف عن الشُّذُوذ [11] إلى ثلاث فئات رَئِيسَِةٍ تتضمن أحد عشر نموذجاً مختلفاً:
1. اِسْتِخْرَاج الميزات (Features Extraction)
2. تَعَلُّم التَمْثيلِات الطبيعية (Learning Representations of Normality)
3. التَّعَلُّم القائم على درجة الشُّذُوذ (Anomaly Score Learning)
يُوضِح الْمُخَطَّط الهرمي في الشكل 4 الفئات الثلاث مع فروعها، بالإضافة إِلَى التَّحَدِّيَات الَّتِي تُعَالِجُهَا تِلْكَ الطرائق. لِيَظْهَر تَفَوَّق شبكة الترميز الآلي (Autoencoder) ضمن فئة تَعلُّم التَمْثيلِات الطبيعية، وذلك من خلال عَدَدِ التَّحَدِّيَات الَّتِي تُعَالِجُهَا (التَّحَدّي 1-5)؛ لَكن تحديد عَتَبَةِ التَّصْنِيف على نحوٍ ديناميكي يبقى أحد أهم التحديات التي ما زال العمل قائماً عليها، وهو الْأَمْر الَّذِي تُعَانِي مِنْهُ جميع طرائق كشف الشُّذُوذ القائمة على التَّعَلُّم الْعَمِيق.
تَتَفَوَّق طرائق التَّعَلُّم الْعَمِيق على طرائق الكشف السابقة بِقُدْرَتِهَا عَلَى التَّعَامُل مَعَ كُلَّ التَّحَدِّيَات السابقة إلى حَدٍّ ما. لذلك تكون قادرة على تَحْقِيق اِسْتِرْجَاع أعلى للحالات الشَّاذَّة، وَتَعْلّم الأنماط والعلاقات الْمُعَقَّدَة في البيانات عَالِيَّة الْأَبْعَاد والسلاسل الزمنية، فَضْلاً عَنْ قُدْرَتِهَا على التَّعَامُل مَعَ جميع أنواع الشُّذُوذ.
| · Distance-based measures as Deep Networks based Random Distance [12] |
| · One-class measures as combine one-class SVM with CNN [13] |
| · Clustering-based measures as deep autoencoding Gaussian mixture model [14] |
| · Rankin models as combine Random Forest with Deep Learning [15] |
| · Prior-driven models as Bayesian inverse reinforcement learning [16] |
| · Soft max models as Deep Networks based likelihood [17] |
2-1 أساليب التلخيص Summarization techniques في اكتشاف الشذوذ
تعد من الطرائق غير المباشرة والمساعدة في اكتشاف الشُّذُوذ، ويمكن دمجها مع خوارزميات التعلم الآلة لتحسين دقة الاكتشاف. تلعب أساليب التلخيص دوراً هاماً في اكتشاف الشُّذُوذ في البيانات، حيث تُمكن من تحويل البيانات إلى تمثيل مُختصر يُسهل عملية تحديد النقاط الشَّاذَّة.
مميزات استخدام أساليب التلخيص في اكتشاف الشُّذُوذ:
- كفاءة الحساب: تُقلل أساليب التلخيص من حجم البيانات، مما يُحسّن من كفاءة الخوارزميات المُستخدمة في اكتشاف الشُّذُوذ.
- فعالية الاكتشاف: تُمكن أساليب التلخيص من إبراز السمات المُهمة في البيانات، ممّا يُسهل عملية تحديد النقاط الشَّاذَّة التي تختلف عن السلوك الطبيعي.
- التعامل مع البيانات الضخمة: تُعدّ أساليب التلخيص مُناسبةً للتعامل مع مجموعات البيانات الضخمة، حيث تُقلل من حجم البيانات قبل تطبيق خوارزميات اكتشاف الشُّذُوذ.
· أنواع أساليب التلخيص المستخدمة في اكتشاف الشُّذُوذ:
- التحليل العنقودي Cluster Analysis:
يُجمع هذا الأسلوب نقاط البيانات معاً بناءً على أوجه التشابه ويُشير إلى المجموعات التي تختلف بشكلٍ كبير عن المجموعات الأخرى كنقاط شاذة.
- التقليل من الأبعاد Dimensionality Reduction:
يُقلل هذا الأسلوب من عدد أبعاد البيانات مع الحفاظ على المعلومات المهمة، ويُشير إلى نقاط البيانات التي تقع بعيداً عن البيانات المُقللة الأبعاد كنقاط شاذة.
- التقريب Approximation:
يُستخدم هذا الأسلوب لإنشاء نموذج مبسط للبيانات، ويُشير إلى نقاط البيانات التي تختلف بشكلٍ كبير عن النموذج كنقاط شاذة.
· أمثلة على تطبيقات أساليب التلخيص في اكتشاف الشذوذ:
- كشف الاحتيال:
يمكن استخدام أساليب التلخيص لتحديد المعاملات الاحتيالية في بيانات بطاقات الائتمان من خلال تحليل أنماط الإنفاق.
- اكتشاف الأخطاء الصناعية:
يمكن استخدام أساليب التلخيص لتحديد المنتجات المعيبة في خط الإنتاج من خلال تحليل بيانات مستشعرات الجودة.
- اكتشاف التسلل الشبكي:
يمكن استخدام أساليب التلخيص لتحديد السلوك الشبكي الضار من خلال تحليل بيانات حركة المرور على الشبكة.
3-الخاتمة والاستنتاجات
أَصْبَحَ واضحاً من خلال ما تم ذكره سابقاً أهمية اكتشاف السلوكيات غير الطبيعية ضِمْنَ النظام المدروس أثناء عملية تحليل البيانات. تُدلُّ هذه السلوكيات على تلاعب من قبل شخص أو جهة مجهولة للحصول على فوائد ومكاسب من النظام بطرق غير شرعية، أو على وجود خلل مَا ضِمْنَ النظام.
تَعدُّ أدوات وأنظمة الْكَشْف عَنِ الشُّذُوذ من أهم الوسائل لاكتشاف هذه الحالات المغايرة للسلوك الطبيعي وفقاً لعمل النظام المدروس. تُعْتَبِرُ طرائق تَعَلُّم العميق من أهم طرائق الكشف استناداً لمّا تَمَّ الإشارة إليه ضِمْنَ أدبيات الدراسات المرجعية.