
إعداد الطالبة : وداع عدنان العثمان
كلية الهندسة -المعلوماتية- الجامعة الوطنية الخاصة

إشراف: د. علي ياسين
كلية الهندسة - المعلوماتية - الجامعة الوطنية الخاصة
الملخص
تتمحور فاعلية الأنظمة المعلوماتية الحديثة حول قدرتها على معالجة البيانات واستقراء النتائج، إلا أن اعتمادها الحصري على “البيانات المسجلة” يضع قيوداً جوهرية على إدراكها للواقع المعقد. تهدف هذه الدراسة إلى تقديم إطار نظري مبتكر يتجاوز المفاهيم التقليدية للمعلومة، من خلال تأصيل مفهوم “المعلومات غير المكتشفة“ وتسليط الضوء بشكل خاص على “البيانات الممكنة“ (Possible Data)؛ وهي البيانات التي يتيح المنطق وجودها ضمن سياقات معينة دون أن تبلغ حيز التحقق الفعلي.
اعتمد البحث على المنهج التحليلي النظري لبناء نموذج مفاهيمي ثلاثي الطبقات يوضح الفجوة المعرفية بين “الموجود” و”الممكن”. وتخلص الدراسة إلى أن دمج فضاء الإمكان في تحليل الأنظمة المعلوماتية يساهم في تقليل درجة عدم اليقين، ويعزز من قدرة نماذج الذكاء الاصطناعي على التعميم (Generalization) ومواجهة السيناريوهات النادرة. يوفر هذا البحث إطاراً فكرياً يساعد المطورين والباحثين على فهم الحدود المعرفية للأنظمة، مما يمهد الطريق لتطوير تقنيات أكثر وعياً بالبيانات الغائبة والمحتملة.
الكلمات المفتاحية: المعلومات غير المكتشفة، البيانات الممكنة، الفجوة المعرفية، حدود المعرفة، الأنظمة المعلوماتية.
Abstract
The efficacy of modern information systems is fundamentally centered on their ability to process data and extrapolate results. However, their exclusive reliance on “recorded data” imposes significant constraints on their perception of a complex reality. This study aims to present an innovative theoretical framework that transcends traditional information concepts by consolidating the concept of “Undiscovered Information” and specifically highlighting “Possible Data”; which refers to data that logic allows to exist within specific contexts without having reached the stage of actual realization.
The research employs a theoretical analytical methodology to construct a three-layered conceptual model that illustrates the Knowledge Gap between the “actual” and the “possible.” The study concludes that integrating the “space of possibility” into the analysis of information systems contributes to reducing uncertainty and enhances the ability of Artificial Intelligence (AI) models to achieve better Generalization and handle rare scenarios. This research provides a conceptual framework that assists developers and researchers in understanding the cognitive boundaries of systems, paving the way for the development of technologies that are more aware of absent and potential data.
Keywords: Undiscovered Information, Possible Data, Knowledge Gap, Knowledge Boundaries, Information Systems.
-المقدمة
أصبحت الأنظمة المعلوماتية في العصر الحديث ركيزة أساسية لا غنى عنها في ميادين متنوعة كالتعليم، والصحة، والتجارة، والذكاء الاصطناعي. وتعتمد فعالية هذه الأنظمة وقدرتها على التحليل والتنبؤ واتخاذ القرار بشكل مباشر على جودة وشمولية البيانات المتاحة لها ]1[.
ورغم القفزات التقنية في معالجة البيانات، تظل هذه الأنظمة مقيدة بمشكلة بنيوية؛ وهي اعتمادها الحصري على البيانات المتوفرة والمسجلة[1]، مما يؤدي إلى تقديم صورة جزئية وغير مكتملة عن الواقع. انطلاقاً من هذا القصور، يبرز مفهوم “المعلومات غير المكتشفة” ليشمل كافة البيانات التي تقع خارج نطاق إدراك النظام، سواء كانت موجودة في الواقع ولم تُسجل، أو كانت تندرج تحت ما يُعرف بـ “البيانات الممكنة”[2]. ويشير مفهوم البيانات الممكنة تحديداً إلى تلك البيانات التي يتيح المنطق وجودها ضمن ظروف معينة، لكنها لم تتحقق فعلياً أو لم يتم رصدها بعد. تسعى هذه الدراسة من خلال منهج تحليلي نظري إلى توسيع الإطار التقليدي للمعلومات، عبر دمج هذه المفاهيم الجديدة لتفسير الفجوة المعرفية وتحسين جودة النمذجة في الأنظمة المعلوماتية المعقدة
1-2مشكلة البحث
تتمثل المشكلة الجوهرية في أن الأنظمة المعلوماتية الحالية، رغم تطورها، لا تزال تعمل ضمن “انغلاق معرفي”؛ فهي مصممة لتعالج وتُحلل البيانات التي تم إدخالها أو تسجيلها في قواعد بياناتها فقط. هذا الاعتماد الحصري يولد عدة تحديات بنيوية:
- الانحياز للواقع المسجل (Recorded Reality Bias): تتعامل الأنظمة مع البيانات المتوفرة وكأنها تمثل الحقيقة المطلقة[1]، بينما هي في الواقع مجرد “عينة” محدودة من واقع أكثر تعقيداً. هذا يؤدي إلى ما يُعرف بـ “الانحياز المعرفي” للآلة، حيث تُبنى النتائج والتنبؤات على صورة مجتزأة.
- تجاهل فضاء الإمكان (The Possible Data Space): تفتقر الأنظمة الحالية إلى آليات لتمثيل البيانات التي “لم تحدث بعد” أو التي “كان من الممكن أن تحدث” منطقياً. إن إهمال هذه البيانات الممكنة يؤدي إلى فجوة معرفية عميقة، خاصة في الأنظمة التي تتطلب تنبؤاً دقيقاً بالسيناريوهات المستقبلية أو الحالات النادرة.[3]
- محدودية النمذجة في البيئات المعقدة: في البيئات التي تتسم بعدم اليقين (مثل التنبؤات الاقتصادية أو أنظمة الذكاء الاصطناعي)، يؤدي غياب “المعلومات غير المكتشفة” إلى ضعف قدرة النظام على التعميم (Generalization)[4]، مما يجعل استجابة النظام للحالات الجديدة غير دقيقة أو خاطئة تماماً.
خلاصة المشكلة: تكمن المشكلة في وجود “فجوة معرفية” متسعة بين ما يدركه النظام (البيانات المتاحة) وبين ما يحيط به من احتمالات (البيانات الممكنة) ومعلومات مخفية (المعلومات غير المكتشفة). وبدون إطار نظري يدمج هذه الأبعاد، ستظل الأنظمة المعلوماتية قاصرة عن محاكاة الواقع المعقد بشكل شامل وموثوق [2]
1-3أهمية البحث
تكتسب هذه الدراسة أهميتها من كونها تطرح رؤية نقدية وتأصيلية تتجاوز المفاهيم التقليدية لإدارة البيانات، ويمكن تلخيص نقاط الأهمية في الأبعاد التالية:
- الأهمية النظرية والمعرفية: تساهم الدراسة في تقديم تعريف شامل لمفهوم “البيانات الممكنة“، مما يفتح آفاقاً جديدة لفهم “الفجوة المعرفية” في الأنظمة التقنية. فهي تقدم إطاراً فلسفياً ومنطقياً يفسر طبيعة المعلومات التي تقع خارج حدود الرصد المباشر، مما يعزز من وعي المطورين بحدود المعرفة الرقمية.
- تطوير نماذج ذكاء اصطناعي أكثر مرونة: تبرز أهمية البحث في قدرته على تقديم تفسير نظري لمشكلات “التعميم” (Generalization) في نماذج الذكاء الاصطناعي. فمن خلال إدراك “البيانات الممكنة”، يمكن بناء نماذج أكثر قدرة على التعامل مع الحالات النادرة والسيناريوهات غير المتوقعة التي لم تتوفر في بيانات التدريب الأصلية.
- رفع كفاءة وموثوقية اتخاذ القرار: تساعد هذه الدراسة في تحسين جودة مخرجات الأنظمة المعلوماتية عبر التنبيه إلى مخاطر “الانحياز للواقع المسجل“. إن فهم الفارق بين المعلومات المكتشفة والممكنة يقلل من درجة عدم اليقين في أنظمة التنبؤ (كأنظمة الطقس والاقتصاد)، مما يؤدي إلى قرارات أكثر دقة وواقعية.
- توفير إطار منهجي للتقييم (النموذج الطبقي): يقدم البحث أداة تحليلية متمثلة في “النموذج الثلاثي الطبقات“، والذي يمكن استخدامه كمعيار لتقييم مدى شمولية الأنظمة المعلوماتية وتحديد مكامن النقص في تمثيل الواقع، مما يمهد الطريق لتطوير تقنيات استشعار ومعالجة أكثر ذكاءً.
- مواكبة التوجهات التقنية الحديثة: تأتي هذه الدراسة في وقت تتجه فيه الأنظمة نحو “البيانات التوليدية” (Synthetic Data) والمحاكاة الرقمية، حيث يمثل مفهوم البيانات الممكنة الأساس النظري لهذه التقنيات التي تسعى لملء الفراغات المعلوماتية في البيئات المعقدة.[5]
1-4منهجية البحث
تعتمد هذه الدراسة على المنهج التحليلي النظري (Analytical Theoretical Approach)، حيث يتم تناول المفاهيم الأساسية في مجال الأنظمة المعلوماتية ونظرية المعلومات من خلال تحليلها وإعادة تركيبها ضمن إطار مفاهيمي جديد.
تقوم المنهجية على ثلاث مراحل رئيسية:
- تحليل المفاهيم التقليدية للمعلومات والتمييز بين البيانات والمعلومات والمعرفة
- دراسة مفهوم المعلومات غير المكتشفة وتحديد أنواعه
- تطوير نموذج مفاهيمي يدمج بين المعلومات المكتشفة وغير المكتشفة والبيانات الممكنة، بهدف تفسير الفجوة المعرفية في الأنظمة المعلوماتية.
لا يعتمد البحث على بيانات تجريبية أو تطبيقات عملية، بل يركز على البناء النظري وتوسيع الإطار المفاهيمي، مع الاستناد إلى الأدبيات العلمية ذات الصلة في نظرية المعلومات والذكاء الاصطناعي.
1-5مساهمة البحث:
تتمثل مساهمة هذا البحث في:
- تقديم إطار مفاهيمي ثلاثي الطبقات للمعلومات.
- التمييز النظري بين المعلومات غير المكتشفة والبيانات الممكنة.
- تفسير الفجوة المعرفية ضمن الأنظمة المعلوماتية الحديثة.
2-الإطار النظري “نظرية المعلومات”
تُعد المعلومات أحد المفاهيم الجوهرية في فضاء الأنظمة المعلوماتية، والمحرك الأساسي لجميع وظائفها الحيوية .[6] ورغم شيوع استخدام هذا المصطلح، إلا أن دلالاته تتعدد وتتباين وفقاً للسياقات التقنية، العلمية، والفلسفية التي يُطرح من خلالها [13]. وبشكل عام، تُعرف المعلومات بأنها بيانات خضعت لعمليات معالجة وتنظيم أكسبتها معنىً وجعلتها قابلة للاستخدام؛ فبينما تمثل البيانات حقائق خامة ومجردة، تتحول إلى معلومات بمجرد تفسيرها وربطها بسياق محدد. [8], [7]
أما المعرفة، فتمثل المرتبة العليا في هذا التسلسل، حيث يتم توظيف المعلومات في عمليات الفهم المعمق واتخاذ القرار. وبناءً على ذلك، يمكن التمييز بين ثلاثة مستويات رئيسية:
- البيانات (Data): وهي مجموعة القيم أو الحقائق الأولية التي تفتقر للمعنى في صورتها المنفردة. [9]
- المعلومات (Information): وهي نتاج معالجة البيانات وتنظيمها لتكتسب دلالة واضحة. [9]
- المعرفة (Knowledge): وهي الفهم المستنير الناتج عن تحليل المعلومات واستثمارها في حل المشكلات واتخاذ القرارات. [9]
تتجلى أهمية هذا التمايز في استيعاب بنية الأنظمة المعلوماتية؛ فهذه الأنظمة لا تعالج المعرفة بصورة مباشرة، بل ترتكز في مدخلاتها على البيانات والمعلومات. لذا، فإن أي خلل أو نقص في مستوى البيانات يؤدي بالضرورة إلى قصور في جودة المعلومات، مما ينعكس سلباً على المعرفة المتولدة عنها. [1]
كما ترتبط المعلومات ارتباطاً وثيقاً بآليات اتخاذ القرار؛ إذ تعمل كمدخلات جوهرية لتحليل البدائل وتقييم المخرجات المتوقعة [14]. فبقدر دقة المعلومات وشموليتها، تزداد فعالية القرارات الناتجة؛ وفي المقابل، يؤدي غياب المعلومات أو نقصها إلى رفع مستويات عدم اليقين، مما يضعف جودة المخرجات النهائية.[10]
وفي سياق هذه الدراسة، يكتسب مفهوم المعلومات بُعداً أكثر رحابة؛ فهو لا ينحصر فيما هو مودع فعلياً داخل الأنظمة، بل يمتد لاستيعاب “المعلومات غير المكتشفة” و”البيانات الممكنة”. إن هذا المنظور يدفعنا لإعادة تعريف المعلومة ليس ككيان ساكن وموجود فحسب، بل كجزء من فضاء معرفي أوسع يضم الممكن وغير المدرك. [2]
3-المعلومات غير المكتشفة وتصنيفها
يُعد مفهوم المعلومات غير المكتشفة من الأطروحات الحديثة نسبياً في أدبيات الأنظمة المعلوماتية؛ إذ يسلط الضوء على الأبعاد غير المرئية من المعرفة، والمتمثلة في تلك المعلومات التي تفتقر للتمثيل الرقمي داخل الأنظمة رغم وجودها الواقعي أو إمكانية تحققها المنطقي. ويساهم هذا المفهوم في رسم الحدود الإدراكية للأنظمة المعلوماتية، مؤكداً أن ما يتم استيعابه داخل هذه الأنظمة لا يعدو كونة انعكاساً جزئياً للواقع المعقد. [2]
ويمكن تعريف المعلومات غير المكتشفة إجرائياً بأنها كافة البيانات التي تقع خارج نطاق الإتاحة أو الرصد أو التدوين داخل النظام، سواء كان ذلك نتيجة لقصور في آليات الجمع، أو تعذر الوصول إليها، أو لعدم تحققها الفعلي في الحيز المادي. وبذلك، فهي تجسد “الفجوة المعرفية” بين الوجود الفعلي والتمثيل الرقمي [1]، ومن أجل فهم أعمق لهذه الظاهرة، يمكن تصنيف المعلومات غير المكتشفة إلى أربعة أنماط رئيسية:
- المعلومات غير المسجلة: وهي الحقائق القائمة في الواقع المادي والتي لم تُدرج في سجلات النظام، إما نتيجة لقصور تقني أو إهمال في أدوات استقصاء البيانات.
مثال: في مستشفى، طبيب لاحظ أن مريضاً يعاني من عرض جانبي نادر بعد تناول دواء معين، لكنه لم يسجل هذا العرض في النظام الإلكتروني بسبب ضغط العمل أو اعتباره غير مهم. لاحقا، عندما يتم تحليل بيانات المرضى لاكتشاف الآثار الجانبية للأدوية، لن يظهر هذا العرض ضمن النتائج [11].
- المعلومات غير القابلة للوصول: وهي البيانات التي قد تكون متوفرة، لكن تحول دون معالجتها قيود تقنية، أو جغرافية، أو زمنية تحجبها عن حيز الإدراك الرقمي.
مثال: شركة تمتلك قاعدة بيانات ضخمة عن سلوك المستخدمين، لكن جزءً منها محفوظ في نظام قديم أو مشفر لا يمكن للأنظمة الحديثة قراءته. عند بناء نموذج ذكاء اصطناعي لتحليل سلوك العملاء، يتم استخدام جزء فقط من البيانات. [11]
- المعلومات غير المعروفة: وتتمثل في البيانات التي يغيب عن وعي النظام أو المستخدم وجودها أصلاً، مما يؤدي إلى عدم السعي لطلبها أو معالجتها.
مثال: قبل اكتشاف فيروس جديد، كانت أعراضه تظهر على بعض المرضى، لكن لم يكن هناك أي تفسير علمي واضح لها. الأنظمة الطبية كانت تسجل الأعراض، لكنها لم تكن قادرة على ربطها بمرض محدد. [11]
- البيانات الممكنة: وهي نمط معرفي خاص يشير إلى البيانات التي يتيح المنطق وجودها لكنها تفتقر للتحقق الفعلي في الواقع ولم تبلغ حيز التسجيل بعد.
مثال: في نظام جامعي، يتم تحليل أداء الطلاب. النظام يحتوي فقط على بيانات الطلاب المسجلين فعليا، لكن لا يحتوي على بيانات الطلاب الذين “كان يمكن أن يسجلوا” ولم يفعلوا. [11]
تتجلى القيمة العلمية لهذا التصنيف في كونه يوضح أن غياب المعلومة لا يعد دليلاً على عدم وجودها، بل هو مؤشر على محدودية وسائل الإدراك أو قصور بنيوي في النظام المعالِج. [9]
ويؤدي هذا القصور إلى نشوء “الفجوة المعرفية” (Knowledge Gap)، وهي التباين القائم بين المعرفة الرقمية المتاحة والمعرفة الشمولية الممكنة. [2]
إن هذه الفجوة تمارس تأثيراً مباشراً وحرجاً على كفاءة الأنظمة؛ فبما أن هذه الأنظمة ترتكز في عملياتها على البيانات المتوفرة حصراً، فإن مخرجاتها التحليلية وقراراتها تظل رهينة “رؤية مجتزأة” للواقع، مما يجعل إغفال المعلومات غير المكتشفة سبباً جوهرياً في إنتاج نتائج تفتقر للدقة والشمول. [9]
ومن أجل توضيح الفروقات المفاهيمية بين أنواع البيانات والمعلومات التي يتعامل معها النظام، يمكن تقديم تصنيف مبسط يبين طبيعة كل نوع من حيث وجوده وعلاقته بالواقع. يساهم هذا العرض في تسهيل فهم الحدود المعرفية للنظام، وإبراز التمايز بين ما هو متاح فعلياً وما يقع خارج نطاق الإدراك المباشر.
الجدول (1) الفرق بين أنواع المعلومات
النوع | التعريف | الحالة |
البيانات المتاحة | بيانات موجودة ومسجلة | موجودة |
المعلومات غير المكتشفة | موجودة لكن غير معروفة | موجودة جزئياً |
البيانات الممكنة | يمكن ان توجد | غير موجودة |
4-البيانات الممكنة: أبعاد المفهوم والتمايز المعرفي
يبرز مفهوم “البيانات الممكنة” كأحد أكثر الركائز تميزاً وأصالة في هذا البحث، إذ يمثل بُعداً نظرياً يتخطى الأطر التقليدية للمعلومات. فهي لا تقتصر في دلالتها على البيانات القائمة أو المفقودة فحسب، بل تمتد لتشمل البيانات التي يتيح المنطق وجودها ضمن سياقات وظروف معينة، رغم افتقارها للتحقق الفعلي في أرض الواقع وغيابها التام عن سجلات الأنظمة المعلوماتية.[6]
ويمكن تعريف البيانات الممكنة إجرائياً بأنها فضاء من القيم والمعلومات التي يستقيم تصور وجودها استناداً إلى منطق النظام أو طبائع الأشياء، دون أن تكون قد بلغت حيز التنفيذ أو الرصد الفعلي. [2] ومن هذا المنطلق، يتبلور فارق جوهري بينها وبين المعلومات غير المكتشفة؛ فبينما تشير الأخيرة إلى معطيات قائمة واقعياً لكنها مجهولة للنظام، تظل البيانات الممكنة في طور “القابلية للوجود” دون ضرورة وجودها الفعلي.
ولجلاء هذا التمايز، يمكن القول إن المعلومات غير المكتشفة ترتبط بما هو “موجود وغير مُدرك”، في حين تتصل البيانات الممكنة بما هو “مُتصور ولم يتحقق”. [6] هذا التوصيف ينقل البيانات الممكنة إلى مستوى أعمق من التحليل المعرفي، بوصفها امتداداً نظرياً وفلسفياً للواقع، وليست مجرد مكونات مخفية ضمن حدوده. [8]
يمكن تقديم بعض الأمثلة لتوضيح هذا المفهوم:
تتضح القيمة التحليلية لمفهوم البيانات الممكنة عند إسقاطه على الأنظمة الواقعية؛ ففي أنظمة التنبؤ بالطقس، تمثل القياسات الغائبة في المناطق غير المغطاة “معلومات غير مكتشفة”، في حين تشكل “البيانات الممكنة” تلك القياسات الافتراضية التي كان من المحتمل رصدها لو أُنشئت محطات رصد إضافية لم توجد أصلاً. وفي أنظمة إدارة المستخدمين، تبرز حسابات الأفراد غير المسجلين كمعلومات غائبة عن قاعدة البيانات، بينما يمثل الأشخاص الذين امتلكوا خيار إنشاء حسابات ولم يفعلوا ذلك “بيانات ممكنة”.
أما في أنظمة الذكاء الاصطناعي، فيبدو المفهوم أكثر حرجاً؛ إذ تمثل الحالات والسيناريوهات التي لم تشملها عملية التدريب “بيانات ممكنة”، حيث كان من المتاح منطقياً تضمينها في مصفوفة التدريب لكنها لم تُستخدم فعلياً. وتكمن أهمية البيانات الممكنة هنا في قدرتها على توسيع المدارك التحليلية حول المعلومات، بحيث لا يتوقف الاستقصاء عند حدود الموجود الفعلي، بل يمتد ليشمل فضاء الإمكان، مما يساهم في فهم أعمق للفجوات المعرفية الكامنة داخل الأنظمة. [3]
إن إدراك وجود “البيانات الممكنة” يساعد في تفسير القصور الوظيفي والأخطاء التقنية، إذ غالباً ما تعزى هذه الأخطاء إلى غياب بيانات كان من الممكن توفرها ومعالجتها؛ وبالتالي فإن هذه البيانات -رغم طبيعتها غير المتحققة- تمارس تأثيراً غير مباشر على كفاءة النظام.[1]
ومن المنظور النظري، يمكن توصيف البيانات الممكنة كحالة وسيطة تقع في المنطقة الفاصلة بين “الوجود“ و “العدم“؛ فهي ليست متحققة في الواقع الفعلي، لكنها لا تندرج تحت بند المستحيل منطقياً. وهذا التموضع هو ما يمنحها ثقلاً خاصاً في التحليل الفلسفي للمعلومات، ويجعلها أداة معرفية رصينة لفهم تخوم المعرفة البشرية والتقنية.
بناءً على ما تقدم، لا يمكن اختزال البيانات الممكنة في كونها مجرد تصور تجريدي، بل هي عنصر جوهري لفك شفرات طبيعة الأنظمة المعلوماتية، ورسم حدودها، واستشراف آفاق تطويرها المستقبلية.
ولتوضيح الفرق بشكل أكثر دقة بين مفهومي “المعلومات غير المكتشفة” و”البيانات الممكنة”، يمكن إجراء مقارنة تحليلية تبرز الأبعاد الأساسية لكل منهما. يساعد هذا التصنيف في إزالة الالتباس بين المفهومين، خاصة من حيث علاقتهما بالوجود الفعلي وطبيعة حضورهما داخل النظام المعلوماتي.
الجدول (2) الفرق بين البيانات غير المكتشفة والبيانات الممكنة التصنيف المقارن لها
| العنصر | غير المكتشفة | الممكنة |
| الوجود الفعلي | موجودة فعلا | قد لاتكون موجودة |
| داخل النظام | غير موجودة | غير موجودة |
| علاقتها بالواقع | جزء من الواقع الحالي | احتمال في الواقع |
| الحالة | مخفية | افتراضية / محتملة |
5-النموذج المفاهيمي المقترح
بعد استعراض مفاهيم المعلومات غير المكتشفة والبيانات الممكنة، تبرز ضرورة الانتقال من المستوى الوصفي إلى مستوى تنظيمي أكثر تجريداً، يتمثل في صياغة نمذجة نظرية لهذه المفاهيم. ولا ترمي هذه النمذجة إلى بناء نموذج برمجـي أو تطبيقـي مباشر، بل تهدف إلى تقديم إطار فكري يؤصل للعلاقات البينية لمختلف أنماط المعلومات، ويوضح بدقة الحدود المعرفية للأنظمة المعلوماتية. [8]
تُعرف النمذجة في هذا السياق بوصفها عملية تمثيل تجريدي للمفاهيم، تسعى لتبسيط الظواهر المعقدة وتحليلها بمنهجية منظمة، مما يتيح تصوراً واضحاً لكيفية توزيع المعلومات ورصد الأجزاء المُمثلة داخل النظام وتلك القابعة خارجه. وبناءً على ذلك، يمكن اقتراح نموذج نظري يرتكز على تقسيم المعلومات إلى ثلاث طبقات أساسية:[2]
- الطبقة الأولى: المعلومات المكتشفة (Known Information): وتشمل البيانات التي جرى تدوينها فعلياً داخل النظام، بحيث أصبحت قابلة للوصول والمعالجة. تمثل هذه الطبقة “الظاهر” من المعرفة، وهي الركيزة التي تعتمد عليها الأنظمة في عملياتها التحليلية.
- الطبقة الثانية: المعلومات غير المكتشفة (Undiscovered Information): وهي البيانات القائمة في الواقع المادي لكنها لم تدخل حيز التسجيل أو الإدراك التقني. تمثل هذه الطبقة الجزء “المخفي” من المعرفة، والذي يلقي بظلاله على دقة النظام دون أن يكون مرصوداً بشكل مباشر.
- الطبقة الثالثة: البيانات الممكنة (Possible Data): وهي المعلومات التي لم تتبلور في حيز التحقق الفعلي، إلا أن وجودها يظل ممكناً من الناحية المنطقية. تمثل هذه الطبقة الامتداد النظري للمعرفة، مشيرةً إلى فضاء “ما يمكن أن يكون”.
يُظهر هذا النموذج الطبقي أن الأنظمة المعلوماتية تقتصر في تعاملها على الطبقة الأولى، بينما تظل الطبقتان الأخريان خارج نطاق المعالجة المباشرة، مما يولد ما يُعرف بـ “الفجوة المعرفية” (Knowledge Gap)؛ وهي التباين بين المعرفة المتاحة رقمياً والمعرفة الكاملة الممكنة. [2]
علاوة على ذلك، يمكن تعميق هذا النموذج من خلال استحضار ثلاثة أنماط من السيناريوهات:
- الحالة الفعلية: المستندة إلى البيانات المتوفرة داخل النظام.
- الحالة غير المكتشفة: المعتمدة على معطيات قائمة واقعياً لكنها غائبة سجلات النظام.
- الحالة الممكنة: القائمة على بيانات افتراضية يتيحها المنطق.
تكمن القيمة العلمية لهذه النمذجة في قدرتها على توفير فهم أعمق لطبيعة الأنظمة المعلوماتية، كاشفةً عن عملها ضمن حدود معرفية ضيقة لا تستوعب كافة جوانب الواقع المعقد. [9] كما تفتح هذه النماذج آفاقاً لتطوير منهجيات تأخذ في الحسبان البيانات غير المكتشفة والممكنة كأدوات تحليلية، مما يعيد صياغة مفهوم المعلومة وحدودها الرقمية بشكل أكثر شمولاً. [1]
يوضح الشكل الاتي المخطط النظري المقترح للطبقات الثلاث
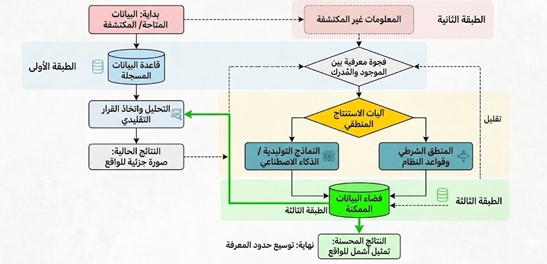
الشكل 1 مخطط تدفقي للانتقال بين الطبقات لاستنتاج البيانات الممكنة
6-تأثير هذه المفاهيم على الأنظمة المعلوماتية
بعد التحليل النظري المعمق لمفهومي المعلومات غير المكتشفة والبيانات الممكنة ونمذجتهما، تبرز ضرورة ملحة لدراسة انعكاسات هذه المفاهيم على الأنظمة المعلوماتية، لا سيما وأن هذه الأنظمة تتخذ من البيانات ركيزة جوهرية لكافة عملياتها الوظيفية. ويؤكد التحليل أن إغفال هذه الأنماط المعلوماتية يفضي بالضرورة إلى نتائج تفتقر للدقة، ويحد بشكل ملموس من قدرة الأنظمة على المحاكاة الكاملة للواقع [1].
تعتمد الأنظمة المعلوماتية في جوهرها على البيانات المتاحة حصراً، مما يعني بقاء أي معلومات غير مسجلة أو غير مكتشفة خارج دائرة المعالجة التقنية. وبناءً عليه، فإن القرارات المنبثقة عن هذه الأنظمة ترتكز على “رؤية مجتزأة” للواقع بدلاً من التمثيل الشامل له، وهو ما يولد نوعاً من الانحياز في المخرجات نتيجة تجاهل المتغيرات غير المرئية أو غير المتوفرة في قواعد البيانات [1] .
ومن أكثر الآثار سلبيةً هو تراجع موثوقية القرارات المتخذة؛ إذ إن عجز البيانات يؤدي حتماً إلى قصور معرفي، مما ينعكس ضعفاً في جودة التحليل النهائي. فالنظام المعلوماتي يعجز عن إنتاج استجابة صحيحة ما لم يستند إلى إحاطة كاملة بملابسات الحالة المعالجة. ويتجلى هذا الأثر بوضوح في أنظمة التنبؤ، كالنماذج المناخية والتحليلات الاقتصادية، التي تعتمد على الاستقراء التاريخي لتوقع المسارات المستقبلية؛ ففي حال غياب البيانات الممكنة أو غير المكتشفة، تصبح التنبؤات أقل دقة وأكثر عرضة لهوامش الخطأ المرتفعة [3] .
أما في فضاء الذكاء الاصطناعي، فيبدو تأثير هذه المفاهيم أكثر حرجاً؛ حيث تعول النماذج على بيانات التدريب لاستنباط الأنماط. فإذا لم تستوعب هذه البيانات كافة الحالات الممكنة، سيقف النموذج عاجزاً عن معالجة السيناريوهات الجديدة أو غير المتوقعة[4]، وهو ما يعرف بضعف القدرة على “التعميم”. علاوة على ذلك، تسهم هذه المفاهيم في رسم الحدود المعرفية للأنظمة، مؤكدةً أنها لا يمكن أن تبلغ حد الكمال أو الشمول المطلق، بل تظل عاملة ضمن نطاق معرفي محدد [3].
يتطلب هذا الواقع من المطورين والمستخدمين إدراكاً واعياً لهذه القيود المعرفية، وتوخي الحذر في الاعتماد المطلق على مخرجات الأنظمة. إن إدماج مفهوم “البيانات الممكنة” يضفي بعداً تحليلياً جديداً يتجاوز حيز الموجود الفعلي ليشمل فضاء الاحتمال المنطقي، مما يعزز من شمولية الرؤية والقدرة على استشراف الحالات غير المدروسة.
ختاماً، لا تعد المعلومات غير المكتشفة والبيانات الممكنة مجرد أطر نظرية مجردة، بل هي محددات فعلية تؤثر في كفاءة الأنظمة المعلوماتية. ومن خلال استيعاب هذه التأثيرات، يمكننا الارتقاء بتصميم الأنظمة وتعميق وعي المستخدم بحدودها التقنية، وصولاً إلى مخرجات أكثر دقة ومحاكاة للواقع المعقد [2].
ومن أجل إبراز الفروقات الجوهرية بين هذه الأنواع من البيانات وتأثير كل منها على كفاءة النظام ودقة مخرجاته، يوضح الجدول التالي مقارنة تحليلية لهذه التأثيرات.
الجدول (3) تأثير كل نوع من البيانات على النظام
| النوع | التأثير على النظام |
| البيانات المتاحة | يعتمد عليها في التحليل |
| المعلومات غير المكتشفة | تسبب نقص في الفهم |
| البيانات الممكنة | تؤثر بشكل غير مباشر |
7-المناقشة
اثبتت النتائج النظرية المستخلصة من هذا البحث أن مفهوم المعلومة في فضاء الأنظمة المعلوماتية يتخطى الأطر التقليدية التي تحصرها في دائرة البيانات المتاحة فحسب. إذ يتضح وجود آفاق معرفية أرحب تشمل المعلومات غير المكتشفة، فضلاً عما يمكن وجوده منطقياً دون أن يتحقق فعلياً، وهو ما يفرض ضرورة إعادة صياغة المنهجيات المتبعة في فهم وتحليل بنية الأنظمة المعلوماتي [2].
ومن أهم القضايا التي يثيرها هذا الطرح هو التساؤل حول مدى قدرة أي نظام معلوماتي على تمثيل الواقع تمثيلاً شمولياً. حيث يشير التحليل إلى أن بلوغ هذا المستوى من المحاكاة الكاملة يظل متعذراً؛ نظراً لوجود عوائق ذاتية وتقنية ومعرفية تحول دون ذلك، فمهما بلغت التقنيات المعتمدة في استقصاء البيانات من تطور، سيبقى هناك دوماً حيز من الواقع غير مُمثل ضمن النطاق الرقمي للنظام [8].
كما كشفت الدراسة أن الركون الكلي إلى البيانات المتوفرة قد يُفضي إلى ما يمكن تسميته بـ “الوهم المعرفي”، حيث يتولد انطباع بأن مخرجات النظام هي الحقيقة المطلقة، بينما هي في جوهرها تعبير عن جزء محدود من الواقع. ومن هنا تبرز الأهمية البالغة لإدراك الفجوة القائمة بين المعرفة المتاحة والمعرفة الممكنة، وتوخي الحذر في اعتبار نتائج الأنظمة حقائق نهائية أو مطلقة [12].
ومن منظور آخر، يفتح تأصيل مفهوم “البيانات الممكنة” مسارات جديدة في تحليل الأنظمة، إذ لا يتوقف التحليل عند حدود الوجود الفعلي، بل يمتد لاستيعاب فضاء الإمكان. إن هذا النمط من التفكير يساهم في توسيع المدارك المعرفية، ويعزز من مرونة الأنظمة وقدرتها على معالجة السيناريوهات غير المتوقعة أو الحالات التي لم تخضع للدراسة المسبقة.
وعلى صعيد أعمق، يمكن مقاربة هذا البحث من زاوية فلسفية تستنطق طبيعة المعرفة وحدودها، وجدلية العلاقة بين المعلومة والواقع [15] ؛ فهل تعمل المعلومات كوسيط ينقل الواقع كما هو، أم أنها مجرد انعكاس مجتزأ له؟ وهل يصح تصنيف “البيانات الممكنة” كنمط من أنماط المعرفة رغم افتقارها للتحقق الفعلي؟ إن هذه التساؤلات تفتح آفاقاً لنقاشات معرفية تتجاوز البعد التقني الصرف [2].
وبالرغم من الطابع النظري الغالب على هذا البحث، فإن الأطروحات المقدمة تمتلك إمكانات تطبيقية واعدة مستقبلاً، لا سيما في مجالات الذكاء الاصطناعي وتحليل البيانات الضخمة؛ حيث يمكن أن تساهم في بناء نماذج أكثر إدراكاً لقصور البيانات، وأكثر كفاءة في إدارة حالات عدم اليقين. وفي الختام، يمكن القول إن هذا البحث لا يسعى لتقديم أحكام قطعية، بقدر ما يطرح إطاراً فكرياً مبتكراً يعمق فهمنا لماهية المعلومات وقيودها. كما يحفز على التفكير في “الغياب” بذات الأهمية الممنوحة “للمتاح”، مما يضفي صبغة من الشمولية والدقة على عملية التحليل المعلوماتي [1].
7-1 التحديات والقيود
رغم الأهمية النظرية لمفهوم البيانات الممكنة والإطار المقترح، إلا أن تطبيقه العملي يواجه عدة تحديات. فمن جهة، يصعب حصر جميع البيانات الممكنة نظراً لاتساع فضاء الإمكان، مما يجعل تمثيلها الكامل أمراً غير قابل للتحقيق. ومن جهة أخرى، يؤدي إدخال هذا النوع من البيانات إلى زيادة التعقيد الحسابي داخل الأنظمة، إضافة إلى غياب آليات واضحة للتحقق من صحة هذه البيانات أو اختبارها تجريبياً. وعليه، فإن هذا المفهوم، رغم قوته التفسيرية، لا يزال بحاجة إلى تطوير منهجي لتحويله إلى أدوات قابلة للتطبيق
بحاجة إلى تطوير منهجي لتحويله إلى أدوات قابلة للتطبيق
8-الخاتمة
استعرضت هذه المقالة مفهوم المعلومات غير المكتشفة بوصفه إطاراً نظرياً جوهرياً يساهم في سبر أغوار الأنظمة المعلوماتية وفهم حدودها البنيوية، مع تركيز خاص على “البيانات الممكنة” كأحد أهم مرتكزات هذا الإطار. وقد خلص التحليل إلى ضرورة التمييز الدقيق بين مستويات ثلاثة للمعلومة: البيانات المتوفرة، المعلومات غير المكتشفة، والبيانات التي يتيحها المنطق دون أن تبلغ حيز التحقق الفعلي. [2]
وقد كشفت الدراسة أن الأنظمة المعلوماتية، برغم ما حققته من قفزات تقنية، لا تزال رهينة “البيانات المتاحة”، مما يحول دون قدرتها على المحاكاة الكاملة للواقع المعقد. هذا القصور يولد فجوة معرفية ملموسة بين المعرفة الرقمية المحصورة والمعرفة الممكنة، وهي فجوة تنعكس آثارها بشكل مباشر على دقة التحليلات ونجاعة القرارات المتخذة. [8]
كما خلصت المقالة إلى أن “البيانات الممكنة” تضفي بعداً تحليلياً حيوياً لفهم هذه الفجوة؛ إذ تسمح باستحضار سيناريوهات افتراضية قابلة للوجود منطقياً وإن غابت واقعياً. إن هذا النمط من التفكير الاستباقي يساهم في توسيع الآفاق التحليلية للأنظمة، ويعزز من كفاءتها في معالجة المتغيرات غير المتوقعة. [3]
وبناءً على ما تقدم، يمكن القول إن إدراك ماهية المعلومات لا ينبغي أن ينحصر في دائرة “المتاح” فقط، بل يستوجب انفتاحاً على “غير المكتشف” و”الممكن”. ومن خلال تبني هذا المنظور الشمولي، يمكن تطوير رؤية استراتيجية للأنظمة المعلوماتية تعي حدود المعرفة الرقمية وتسعى لتقليص فجواتها قدر الإمكان.
وفي الختام، يشرع هذا البحث الأبواب أمام ابتكار نماذج معلوماتية متطورة تتجاوز نمطية البيانات المتاحة، عبر إدماج “فضاء الإمكان” ضمن آليات التحليل والاستشراف. ومن المتوقع أن يساهم هذا الإطار في الارتقاء بأداء أنظمة الذكاء الاصطناعي، لاسيما في تعزيز قدرتها على “التعميم” والتعامل بمرونة مع حالات عدم اليقين والسيناريوهات النادرة التي لم تدرج ضمن بيانات التدريب الأولية.
المراجع:
[1] C. Batini and M. Scannapieco, Data Quality: Concepts, Methodologies and Techniques. Springer, 2006.
[2] L. Floridi, Information: A Very Short Introduction. Oxford, UK: Oxford University Press, 2010.
[3] S. Russell and P. Norvig, Artificial Intelligence: A Modern Approach, 4th ed. Pearson, 2021.
[4] S. Liu et al., “Out-of-Distribution Generalization in Time Series: A Survey,” arXiv preprint arXiv:2503.13868, 2025. [Online]. Available: https://arxiv.org/abs/2503.13868
[5] M. Goyal and Q. H. Mahmoud, “A Systematic Review of Synthetic Data Generation Techniques Using Generative AI,” Electronics, vol. 13, no. 17, p. 3387, Aug. 2024. [Online]. Available: https://doi.org/10.3390/electronics13173387
[6] M. Miller, B. Schölkopf, and S. Guo, “Counterfactual Reasoning: An Analysis of In-Context Emergence,” in Proc. 38th Conf. Neural Inf. Process. Syst. (NeurIPS 2024), 2024. [Online]. Available: https://arxiv.org/abs/2506.05188
[7] C. E. Shannon, “A Mathematical Theory of Communication,” Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948. [Online]. Available: https://ieeexplore.ieee.org/document/6773024
[8] T. M. Cover and J. A. Thomas, Elements of Information Theory, 2nd ed. Hoboken, NJ, USA: Wiley, 2006.
[9] J. Han, M. Kamber, and J. Pei, Data Mining: Concepts and Techniques, 3rd ed. Waltham, MA, USA: Morgan Kaufmann, 2011.
[10] “Information Systems and Knowledge Management: Theoretical Perspective of Associated Interconnection,” in Proc. Int. Conf. Bus. Econ. (ICBE 2025), Jan. 2025. [Online]. Available: https://www.researchgate.net/publication/397175297
[11] N. Sambasivan, S. Kapania, H. Highfill, D. Akrong, P. Paritosh, and L. Aroyo, “Everyone Wants to Do the Model Work, Not the Data Work: Data Cascades in High-Stakes AI,” in Proc. ACM Conf. Human Factors Comput. Syst. (CHI), 2021. [Online]. Available: https://doi.org/10.1145/3411764.3445518
[12] L. Floridi, The Philosophy of Information. Oxford, UK: Oxford University Press, 2011.
[13] C. E. Shannon and W. Weaver, The Mathematical Theory of Communication. Urbana, IL, USA: University of Illinois Press, 1949.
[14] S. Shamai and A. Zaidi, “Information Theory for Data Communications and Processing,” Entropy, vol. 22, no. 4, p. 432, 2020. [Online]. Available: https://doi.org/10.3390/e22040432
[15] J. Gleick, The Information: A History, a Theory, a Flood. Pantheon Books, 2011.